
Mateen Ulhaq
Software Engineer
I am a former Master’s student from Simon Fraser University. I am interested in deep learning, artificial intelligence, programming languages (e.g. Python, C++, Rust, Haskell, etc.), compilers, compression, open source, Linux, terminal code editors (Neovim), mathematics, image processing, photography, and physics.
Some fun projects I’ve worked on:
- Building a mini autograd engine (Python) [Slides]
- CompressAI Trainer (Python)
- Particle filter likelihood kernel on FPGA and GPU (C++, HLS, CUDA) [Slides]
- Chess engine (Rust)
- Frece: frecency indexed database (Rust)
- Dotfiles
- Easy slurm (Python)
- Scrobblez: customizable last.fm scrobbler (Python)
- Improving the tactical awareness of deep neural network chess engines (Python) [Report]
- Chess “play all moves” challenge webapp (JavaScript)
- Fruit tetris game (C++, OpenGL)
Publications
Mateen Ulhaq,
Ivan V. Bajić,
Learned Compression of Encoding Distributions
Learned Compression of Encoding Distributions
In IEEE ICIP,
2024.
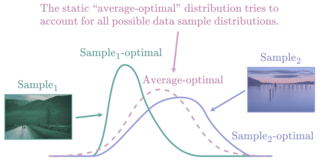
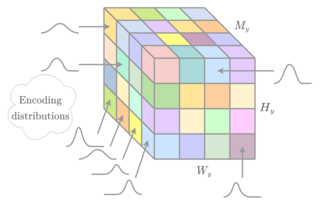
The entropy bottleneck introduced by Ballé et al. is a common component used in many learned compression models.
It encodes a transformed latent representation using a static distribution whose parameters are learned during training.
However, the actual distribution of the latent data may vary wildly across different inputs.
The static distribution attempts to encompass all possible input distributions, thus fitting none of them particularly well.
This unfortunate phenomenon, sometimes known as the amortization gap, results in suboptimal compression.
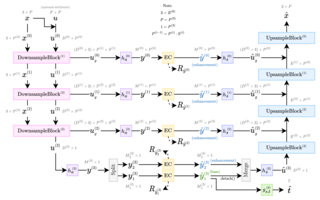
To address this issue, we propose a method that dynamically adapts the encoding distribution to match the latent data distribution for a specific input.
First, our model estimates a better encoding distribution for a given input.
This distribution is then compressed and transmitted as an additional side-information bitstream.
Finally, the decoder reconstructs the encoding distribution and uses it to decompress the corresponding latent data.
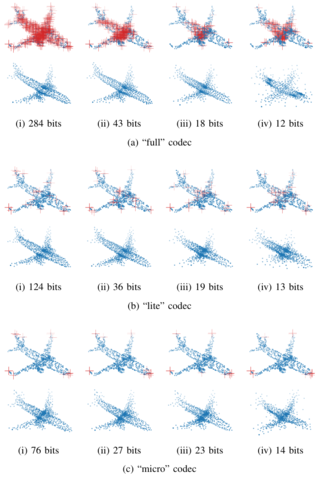
Our method achieves a Bjøntegaard-Delta (BD)-rate gain of -7.10% on the Kodak test dataset when applied to the standard fully-factorized architecture.
Furthermore, considering computational complexity, the transform used by our method is an order of magnitude cheaper in terms of Multiply-Accumulate (MAC) operations compared to related side-information methods such as the scale hyperprior.
Mateen Ulhaq,
Ivan V. Bajić,
Scalable Human-Machine Point Cloud Compression
Scalable Human-Machine Point Cloud Compression
In Picture Coding Symposium (PCS),
2024.
Due to the limited computational capabilities of edge devices, deep learning inference can be quite expensive.
One remedy is to compress and transmit point cloud data over the network for server-side processing.
Unfortunately, this approach can be sensitive to network factors, including available bitrate.
Luckily, the bitrate requirements can be reduced without sacrificing inference accuracy by using a machine task-specialized codec.
In this paper, we present a scalable codec for point-cloud data that is specialized for the machine task of classification, while also providing a mechanism for human viewing.
In the proposed scalable codec, the "base" bitstream supports the machine task, and an "enhancement" bitstream may be used for better input reconstruction performance for human viewing.
We base our architecture on PointNet++, and test its efficacy on the ModelNet40 dataset.
We show significant improvements over prior non-specialized codecs.
Mateen Ulhaq,
Master's thesis: Learned Compression for Images and Point Clouds
Master's thesis: Learned Compression for Images and Point Clouds
In Simon Fraser University,
2023.
Over the last decade, deep learning has shown great success at performing computer vision tasks, including classification, super-resolution, and style transfer.
Now, we apply it to data compression to help build the next generation of multimedia codecs.
This thesis provides three primary contributions to this new field of learned compression.
First, we present an efficient low-complexity entropy model that dynamically adapts the encoding distribution to a specific input by compressing and transmitting the encoding distribution itself as side information.
Secondly, we propose a novel lightweight low-complexity point cloud codec that is highly specialized for classification, attaining significant reductions in bitrate compared to non-specialized codecs.
Lastly, we explore how motion within the input domain between consecutive video frames is manifested in the corresponding convolutionally-derived latent space.
Mateen Ulhaq,
Ivan V. Bajić,
Learned Point Cloud Compression for Classification
Learned Point Cloud Compression for Classification
In IEEE MMSP,
2023.
Deep learning is increasingly being used to perform machine vision tasks such as classification, object detection, and segmentation on 3D point cloud data.
However, deep learning inference is computationally expensive.
The limited computational capabilities of end devices thus necessitate a codec for transmitting point cloud data over the network for server-side processing.
Such a codec must be lightweight and capable of achieving high compression ratios without sacrificing accuracy.
Motivated by this, we present a novel point cloud codec that is highly specialized for the machine task of classification.
Our codec, based on PointNet, achieves a significantly better rate-accuracy trade-off in comparison to alternative methods.
In particular, it achieves a 94% reduction in BD-bitrate over non-specialized codecs on the ModelNet40 dataset.
For low-resource end devices, we also propose two lightweight configurations of our encoder that achieve similar BD-bitrate reductions of 93% and 92% with 3% and 5% drops in top-1 accuracy, while consuming only 0.470 and 0.048 encoder-side kMACs/point, respectively.
Our codec demonstrates the potential of specialized codecs for machine analysis of point clouds, and provides a basis for extension to more complex tasks and datasets in the future.
Ezgi Özyılkan,
Mateen Ulhaq,
Hyomin Choi,
Fabien Racapé,
Learned disentangled latent representations for scalable image coding for humans and machines
Learned disentangled latent representations for scalable image coding for humans and machines
In IEEE DCC,
2023.
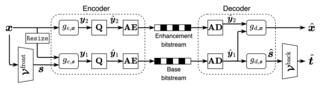
As an increasing amount of image and video content will be analyzed by machines, there is demand for a new codec paradigm that is capable of compressing visual input primarily for the purpose of computer vision inference, while secondarily supporting input reconstruction.
In this work, we propose a learned compression architecture that can be used to build such a codec.
We introduce a novel variational formulation that explicitly takes feature data relevant to the desired inference task as input at the encoder side.
As such, our learned scalable image codec encodes and transmits two disentangled latent representations for object detection and input reconstruction.
We note that compared to relevant benchmarks, our proposed scheme yields a more compact latent representation that is specialized for the inference task.
Our experiments show that our proposed system achieves a bit rate savings of 40.6% on the primary object detection task compared to the current state-of-the-art, albeit with some degradation in performance for the secondary input reconstruction task.

Hyomin Choi,
Fabien Racapé,
Shahab Hamidi-Rad,
Mateen Ulhaq,
Simon Feltman,
Frequency-aware Learned Image Compression for Quality Scalability
Frequency-aware Learned Image Compression for Quality Scalability
In IEEE VCIP,
2022.
Spatial frequency analysis and transforms serve a central role in most engineered image and video lossy codecs, but are rarely employed in neural network (NN)-based approaches.
We propose a novel NN-based image coding framework that utilizes forward wavelet transforms to decompose the input signal by spatial frequency.
Our encoder generates separate bitstreams for each latent representation of low and high frequencies.
This enables our decoder to selectively decode bitstreams in a quality-scalable manner.
Hence, the decoder can produce an enhanced image by using an enhancement bitstream in addition to the base bitstream.
Furthermore, our method is able to enhance only a specific region of interest (ROI) by using a corresponding part of the enhancement latent representation.
Our experiments demonstrate that the proposed method shows competitive rate-distortion performance compared to several non-scalable image codecs.
We also showcase the effectiveness of our two-level quality scalability, as well as its practicality in ROI quality enhancement.
Saeed Ranjbar Alvar,
Mateen Ulhaq,
Hyomin Choi,
Ivan V. Bajić,
Joint Image Compression and Denoising via Latent-Space Scalability
Joint Image Compression and Denoising via Latent-Space Scalability
In Frontiers in Signal Processing,
2022.
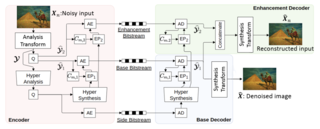
When it comes to image compression in digital cameras, denoising is traditionally performed prior to compression.
However, there are applications where image noise may be necessary to demonstrate the trustworthiness of the image, such as court evidence and image forensics.
This means that noise itself needs to be coded, in addition to the clean image itself.
In this paper, we present a learning-based image compression framework where image denoising and compression are performed jointly.
The latent space of the image codec is organized in a scalable manner such that the clean image can be decoded from a subset of the latent space (the base layer), while the noisy image is decoded from the full latent space at a higher rate.
Using a subset of the latent space for the denoised image allows denoising to be carried out at a lower rate.
Besides providing a scalable representation of the noisy input image, performing denoising jointly with compression makes intuitive sense because noise is hard to compress; hence, compressibility is one of the criteria that may help distinguish noise from the signal.
The proposed codec is compared against established compression and denoising benchmarks, and the experiments reveal considerable bitrate savings compared to a cascade combination of a state-of-the-art codec and a state-of-the-art denoiser.
Mateen Ulhaq,
Ivan V. Bajić,
Latent Space Motion Analysis for Collaborative Intelligence
Latent Space Motion Analysis for Collaborative Intelligence
In IEEE ICASSP,
2021.
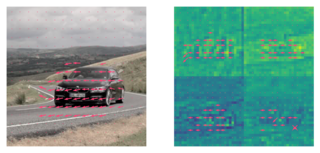
When the input to a deep neural network (DNN) is a video signal, a sequence of feature tensors is produced at the intermediate layers of the model.
If neighboring frames of the input video are related through motion, a natural question is, "what is the relationship between the corresponding feature tensors?"
By analyzing the effect of common DNN operations on optical flow, we show that the motion present in each channel of a feature tensor is approximately equal to the scaled version of the input motion.
The analysis is validated through experiments utilizing common motion models.
Mateen Ulhaq,
Ivan V. Bajić,
ColliFlow: A Library for Executing Collaborative Intelligence Graphs
ColliFlow: A Library for Executing Collaborative Intelligence Graphs
In NeurIPS (demo),
2020.
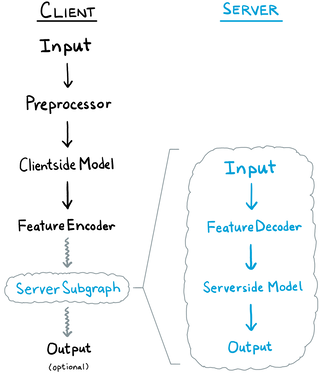
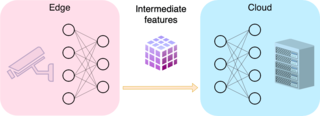
Collaborative intelligence has emerged as a promising strategy to bring "AI to the edge".
In a typical setting, a learning model is distributed between an edge device and the cloud, each part performing its own share of inference.
We present ColliFlow — a library for executing collaborative intelligence graphs — which makes it relatively easy for researchers and developers to construct and deploy collaborative intelligence systems.
Mateen Ulhaq,
Bachelor's thesis: Mobile-Cloud Inference for Collaborative Intelligence
Bachelor's thesis: Mobile-Cloud Inference for Collaborative Intelligence
In Simon Fraser University,
2020.
As AI applications for mobile devices become more prevalent, there is an increasing need for faster execution and lower energy consumption for deep learning model inference.
Historically, the models run on mobile devices have been smaller and simpler in comparison to large state-of-the-art research models, which can only run on the cloud.
However, cloud-only inference has drawbacks such as increased network bandwidth consumption and higher latency.
In addition, cloud-only inference requires the input data (images, audio) to be fully transferred to the cloud, creating concerns about potential privacy breaches.
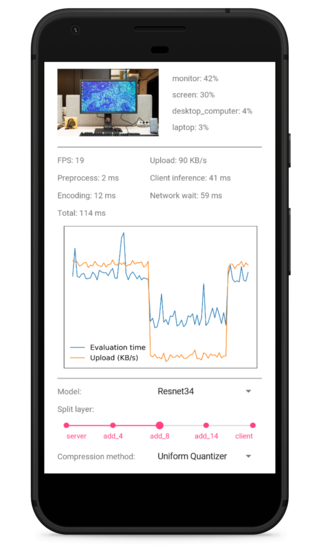
There is an alternative approach: shared mobile-cloud inference.
Partial inference is performed on the mobile in order to reduce the dimensionality of the input data and arrive at a compact feature tensor, which is a latent space representation of the input signal.
The feature tensor is then transmitted to the server for further inference.
This strategy can reduce inference latency, energy consumption, and network bandwidth usage, as well as provide privacy protection, because the original signal never leaves the mobile.
Further performance gain can be achieved by compressing the feature tensor before its transmission.
Mateen Ulhaq,
Ivan V. Bajić,
Shared Mobile-Cloud Inference for Collaborative Intelligence
Shared Mobile-Cloud Inference for Collaborative Intelligence
In NeurIPS (demo),
2019.
As AI applications for mobile devices become more prevalent, there is an increasing need for faster execution and lower energy consumption for neural model inference.
Historically, the models run on mobile devices have been smaller and simpler in comparison to large state-of-the-art research models, which can only run on the cloud.
However, cloud-only inference has drawbacks such as increased network bandwidth consumption and higher latency.
In addition, cloud-only inference requires the input data (images, audio) to be fully transferred to the cloud, creating concerns about potential privacy breaches.
We demonstrate an alternative approach: shared mobile-cloud inference.
Partial inference is performed on the mobile in order to reduce the dimensionality of the input data and arrive at a compact feature tensor, which is a latent space representation of the input signal.
The feature tensor is then transmitted to the server for further inference.
This strategy can improve inference latency, energy consumption, and network bandwidth usage, as well as provide privacy protection, because the original signal never leaves the mobile.
Further performance gain can be achieved by compressing the feature tensor before its transmission.
Cite Learned Compression of Encoding Distributions
@inproceedings{ulhaq2024encodingdistributions,
author = {Ulhaq, Mateen and Bajić, Ivan V.},
author+an:default = {1=me},
booktitle = {Proc. IEEE ICIP},
date = {2024},
pubstate = {submitted},
title = {Learned Compression of Encoding Distributions},
}
Cite Scalable Human-Machine Point Cloud Compression
@inproceedings{ulhaq2024scalablepointcloud,
author = {Ulhaq, Mateen and Bajić, Ivan V.},
author+an:default = {1=me},
booktitle = {Proc. PCS},
date = {2024},
pubstate = {accepted},
title = {Scalable Human-Machine Point Cloud Compression},
}
Cite Master's thesis: Learned Compression for Images and Point Clouds
@thesis{ulhaq2023thesismasc,
author = {Ulhaq, Mateen},
author+an:default = {1=me},
institution = {Simon Fraser University},
date = {2023},
title = {Learned Compression for Images and Point Clouds},
type = {MASc thesis},
}
Cite Learned Point Cloud Compression for Classification
@inproceedings{ulhaq2023pointcloud,
author = {Ulhaq, Mateen and Bajić, Ivan V.},
author+an:default = {1=me},
booktitle = {Proc. IEEE MMSP},
date = {2023},
eprint = {2308.05959},
eprintclass = {eess.IV},
eprinttype = {arXiv},
title = {Learned Point Cloud Compression for Classification},
}
Cite Learned disentangled latent representations for scalable image coding for humans and machines
@inproceedings{ozyilkan2023learned,
author = {Özyılkan, Ezgi and Ulhaq, Mateen and Choi, Hyomin and Racapé, Fabien},
author+an:default = {1=first;2=me,first},
booktitle = {Proc. IEEE DCC},
date = {2023},
eprint = {2301.04183},
eprintclass = {eess.IV},
eprinttype = {arXiv},
pages = {42--51},
title = {Learned disentangled latent representations for scalable image coding for humans and machines},
}
Cite Frequency-aware Learned Image Compression for Quality Scalability
@inproceedings{choi2022frequencyaware,
author = {Choi, Hyomin and Racapé, Fabien and Hamidi-Rad, Shahab and Ulhaq, Mateen and Feltman, Simon},
author+an:default = {4=me},
booktitle = {Proc. IEEE VCIP},
date = {2022},
doi = {10.1109/VCIP56404.2022.10008818},
eprint = {2301.01290},
eprintclass = {eess.IV},
eprinttype = {arXiv},
pages = {1--5},
title = {Frequency-aware Learned Image Compression for Quality Scalability},
}
Cite Joint Image Compression and Denoising via Latent-Space Scalability
@article{alvar2022joint,
author = {Alvar, Saeed Ranjbar and Ulhaq, Mateen and Choi, Hyomin and Bajić, Ivan V.},
author+an:default = {2=me},
publisher = {Frontiers Media {SA}},
date = {2022},
doi = {10.3389/frsip.2022.932873},
eprint = {2205.01874},
eprintclass = {eess.IV},
eprinttype = {arXiv},
journaltitle = {Frontiers in Signal Processing},
title = {Joint Image Compression and Denoising via Latent-Space Scalability},
volume = {2},
}
Cite Latent Space Motion Analysis for Collaborative Intelligence
@inproceedings{ulhaq2021analysis,
author = {Ulhaq, Mateen and Bajić, Ivan V.},
author+an:default = {1=me},
booktitle = {Proc. IEEE ICASSP},
date = {2021},
doi = {10.1109/ICASSP39728.2021.9413603},
eprint = {2102.04018},
eprintclass = {cs.CV},
eprinttype = {arXiv},
pages = {8498--8502},
title = {Latent Space Motion Analysis for Collaborative Intelligence},
}
Cite ColliFlow: A Library for Executing Collaborative Intelligence Graphs
@misc{ulhaq2020colliflow,
author = {Ulhaq, Mateen and Bajić, Ivan V.},
author+an:default = {1=me},
url = {https://yodaembedding.github.io/neurips-2020-demo/},
date = {2020},
note = {demoed at NeurIPS},
title = {{ColliFlow}: A Library for Executing Collaborative Intelligence Graphs},
}
Cite Bachelor's thesis: Mobile-Cloud Inference for Collaborative Intelligence
@thesis{ulhaq2020thesisbasc,
author = {Ulhaq, Mateen},
author+an:default = {1=me},
institution = {Simon Fraser University},
date = {2020},
eprint = {2306.13982},
eprintclass = {cs.LG},
eprinttype = {arXiv},
title = {Mobile-Cloud Inference for Collaborative Intelligence},
type = {BASc honors thesis},
}